
A step-by-step look at integrating OpenAI’s voice API with a domain-aware AI assistant

Voice is rapidly becoming the preferred way to interact with intelligent systems — but making real-time, conversational assistants has long been complex and slow. In this post, we share how we used OpenAI’s Realtime API to add voice capabilities to an existing Python-based Retrieval-Augmented Generation (RAG) chatbot.
The result: a voice-enabled assistant that can listen, reason with domain-specific data, and respond in real time — delivering natural, hands-free interaction with enterprise-grade knowledge.
We also cover key lessons, latency challenges, and how this unified approach simplifies architecture while improving user experience.
How real-time voice connects with RAG under the hood
The Realtime API provides a powerful mechanism to connect audio streams to GPT-4o in both directions.
By opening a WebSocket session, we could send raw microphone input to the model and receive back streaming speech and text responses.
To make this truly conversational, the API also includes built-in voice activity detection (VAD) to automatically detect when users start and stop speaking. This makes the integration ideal for hands-free, natural interactions.
In our case, we added voice on top of an already functional RAG pipeline:
- our backend chatbot exposes a function that receives user input,
- queries a document-based knowledge system,
- and returns a tailored response.
To blend this with the Realtime API, we intercept transcribed speech events from the OpenAI session, send them to our RAG pipeline, and then re-inject the response back into the session — causing the assistant to speak it out loud.
Interaction flow
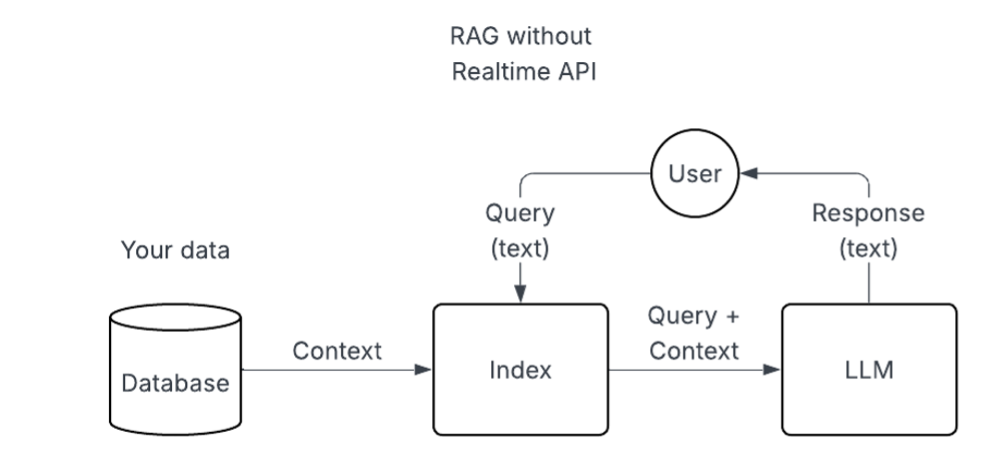
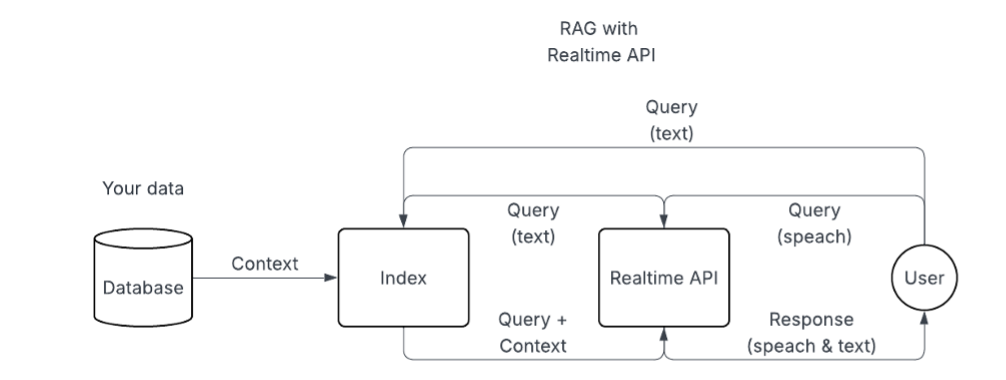
The flow goes like this:
- the user speaks into their microphone;
- the audio is streamed to OpenAI’s model;
- as soon as transcription completes and the user has finished speaking, we send the resulting text into our RAG function.
- That function returns a custom response — often based on internal documents or APIs — which we treat as if the user had typed it, sending it back into the assistant as a conversation turn.
- OpenAI then streams the corresponding audio, which we play back to the user.
The delay
While this works well, one important consideration is the delay introduced by the RAG injection step.
Because we wait for the transcription to complete before triggering retrieval and reinjection, there is currently a noticeable delay — typically a few seconds — between the end of user speech and the start of the assistant’s spoken response.
This is especially evident when RAG queries involve vector database lookups, additional processing, or response formatting.
And how to reduce it
We are actively working on ways to reduce this latency to make the experience feel as close to instant as possible. Several approaches are under exploration:
· One is to better adapt the structure and indexing of the vector database to serve real-time use cases more efficiently. This includes optimizing embeddings, caching likely responses, and streamlining search layers.
· Another path involves improving our integration with the Realtime API’s streaming response capabilities — so we can begin playing the assistant’s answer as soon as the first tokens are available, rather than waiting for the full RAG output.
· We’re also looking into parallelizing parts of the transcription-to-response pipeline and experimenting with partial-response generation to bridge the response gap.
It used to be much worse
Even with the current delay introduced by the RAG step, the modern architecture powered by OpenAI’s Realtime API is significantly more efficient than traditional voice assistant pipelines.
Previously, creating a conversational voice interface required stitching together at least three separate models and APIs:
- one for speech-to-text — like Whisper or another ASR service,
- one for generating a response — typically a text-based LLM,
- and a third for text-to-speech synthesis — such as OpenAI’s TTS AP).
Each step introduced its own latency, integration complexity, and failure points.
With the Realtime API and GPT-4o, speech recognition, reasoning, and speech synthesis are unified in a single multimodal model and connection.
This not only reduces round-trip latency and simplifies implementation but also preserves conversational context and tone more effectively with the more modern and perfected voices, that adapt the tone of voice to the context of the generated response.
The result is a more coherent, more natural interaction — without the overhead of managing three separate pipelines.
Technical perspective: setup and architecture

This setup is powered by Python’s websockets library and OpenAI’s session and conversation event model.
We use sounddevice to capture microphone input and play back audio, and manage the audio buffer manually to ensure low latency and smooth playback.
Our session configuration enables both audio and text modalities and tunes voice activity detection for responsive behavior in different environments.
While OpenAI offers WebRTC for client-side browser integrations, we opted for a WebSocket-based approach in Python to keep everything server-driven and secure.
This also gave us full access to session control, response injection, and low-level audio processing, which are crucial for enterprise-grade integrations.
The business benefits
One of the most compelling benefits of this architecture is how well it supports domain-aware logic.
Unlike general-purpose assistants that rely solely on LLM memory, our RAG integration brings in high-confidence, real-time data from business sources or internal documents. This makes the voice assistant especially useful for users who prefer speaking over typing and need accurate, contextual answers.
Another key benefit is flexibility. The Realtime API allows us to dynamically control whether responses include speech, text, or both.
It also supports turn-level control, so we can determine exactly when the assistant should respond — an essential feature when layering in custom logic like RAG.
Ultimately, adding the Realtime API to a RAG chatbot transforms the interaction from a static search interface into an ongoing conversation.
When paired with robust retrieval and structured outputs, voice becomes not just a modality — but a multiplier:
- It brings intelligence closer to users,
- makes interfaces feel more human,
- and unlocks access for those who prefer to speak rather than type.
What happens next
As the technology matures, we expect voice-first assistants to appear in more workspaces, mobile tools, kiosks, and field service environments.
And with OpenAI’s Realtime API, we now have the building blocks to deliver those experiences — with real-time performance and real-world intelligence.
Voice assistants grow up: how OpenAI’s Realtime API enables contextual, real-time conversation was originally published in ableneo tech & transformation on Medium, where people are continuing the conversation by highlighting and responding to this story.